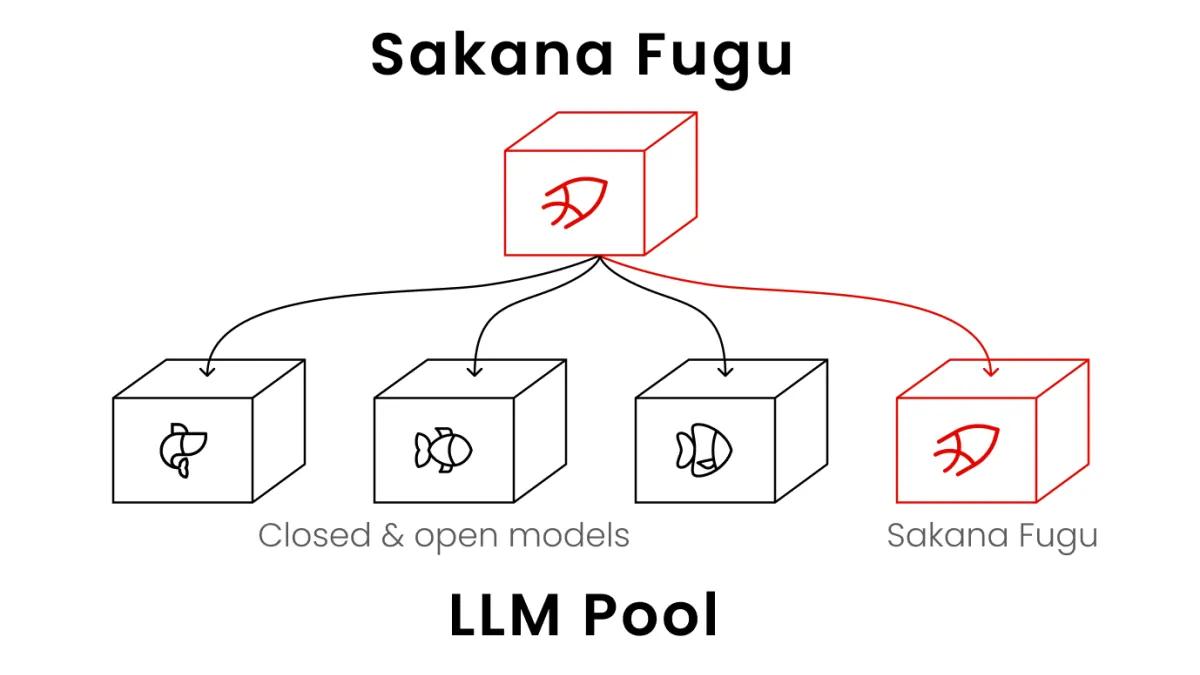
Fugu是一位負責「管理ChatGPT們」的AI。它由日本新創Sakana AI於2026年6月22日推出,屬於多模型編排系統,可透過單一API協調多個前沿模型共同完成任務。
Fugu在日文中意為「河豚」,Sakana則意為「魚」。Sakana AI的公司名稱來自日文「さかな」,官方也曾說明,這個命名象徵魚群聚集、透過簡單規則形成整體智慧的概念。
如果把ChatGPT比喻成一位能力很強的專家,那麼Fugu更像是一位專案經理。
當使用者提出問題後,Fugu不一定自己完成所有工作,而是判斷哪些任務需要搜尋資料、哪些需要寫程式、哪些需要驗證結果,再把工作分派給不同AI模型與代理人處理。對使用者而言,看到的仍然只有一個聊天視窗;但在背後,可能有多個模型同時參與任務。
這種被稱為「模型編排(Model Orchestration)」的架構,是近期AI產業最受關注的新方向之一。日本AI新創Sakana AI於2026年6月22日推出Fugu與Fugu Ultra後,也讓這項原本較偏研究領域的概念正式進入市場。以下透過8個常見問題,快速理解Fugu與傳統大型語言模型的差異。
Q1:Fugu是新的大型語言模型(LLM)嗎?
Fugu本身也是由Sakana AI訓練的語言模型,但它被設計成負責協調其他模型,而非直接包辦所有推理與回答。
Sakana AI將Fugu描述為一套「以單一基礎模型形式提供的多代理協作系統(multi-agent orchestration system as a single foundation model)」。換句話說,它把原本需要企業自行建構的多代理架構,封裝成像單一模型一樣可以呼叫的產品。
這套能力建立在Sakana AI兩項研究成果之上,包括TRINITY與The Conductor。前者讓不同模型分別負責思考、執行與驗證等工作;後者則透過強化學習,讓系統學會如何以自然語言協調不同AI代理人。
因此,Fugu比較像是一個被訓練來判斷「該找誰做什麼」的AI協調模型,而非單純的聊天機器人或一般的模型路由器。
Q2:Fugu和ChatGPT、Claude有什麼不同?
ChatGPT、Claude或Gemini等產品,通常由單一模型完成整個推理過程。使用者提出問題,模型直接生成答案。
Fugu則更像一個指揮系統。當接收到任務後,它會先判斷需要哪些能力,再動態調度代理池(Agent Pool)中的模型共同完成工作。
例如在程式開發任務中,可能有一個模型負責撰寫程式碼,另一個模型負責檢查漏洞,再由其他模型驗證結果是否符合需求。Fugu的角色則是決定如何分工、何時檢查,以及如何把不同模型的輸出整合成最終答案。
因此,使用者看到的是一個AI,但背後實際上可能有多個模型同時協作完成任務。
| 比較項目 | 傳統LLM(ChatGPT/Claude/Gemini) | Sakana Fugu |
|---|
| 完成任務者 | 單一模型 | 多模型協作 |
| 使用方式 | 呼叫單一模型 | 呼叫單一API,背後由系統協調多個模型 |
| 模型管理 | 使用者或開發者自行選擇模型 | 系統根據任務自動調度 |
| 系統擴充 | 主要仰賴更換或升級模型 | 可新增或替換代理池中的模型 |
| 核心價值 | 單一模型能力 | 模型之間的分工、驗證與整合能力 |
Q3:Fugu是自己有模型,還是只是調用別人的模型?
Fugu本身就是Sakana AI訓練出來的模型,但它的工作是協調其他模型。
根據官方說法,Fugu可以調用代理池中的不同大型語言模型,也能呼叫自己的副本參與任務。未來代理池除了第三方模型外,也將逐步納入更多Sakana自研模型與開源模型。
一般模型路由器比較像交通號誌,負責把請求送到某個模型;Fugu則更像專案經理,會決定任務如何拆解、是否需要多個模型協作、結果是否需要驗證,以及最後如何整合。
因此,把Fugu理解成「AI指揮官」會比「模型路由器」更貼切。
Q4:如果OpenAI或Anthropic停止服務,Fugu還能運作嗎?
若企業把核心服務高度綁定單一模型供應商,一旦該模型因技術、商業或法規因素無法提供服務,整個應用都可能受到衝擊。
Fugu的做法是建立多模型架構。若某個模型無法使用,系統可改由其他模型接手相關工作。
不過這並不代表效能完全不受影響。最終表現仍取決於當時可使用模型的能力、數量與任務類型。如果被替換掉的是某個特別擅長程式、數學或科學推理的模型,整體品質仍可能下降。
比較準確的說法是,Fugu能降低對單一供應商的依賴,但無法讓供應鏈風險完全消失。
Q5:Fugu Ultra真的比前沿模型更強嗎?
A:在部分高難度任務上,官方數據顯示它已達到前沿模型水準;但仍要看任務類型。
根據Sakana AI公布的官方測試結果,Fugu Ultra在多項AI基準測試中表現亮眼,包括:
- SWE-Bench Pro:73.7
- TerminalBench 2.1:82.1
- LiveCodeBench:93.2
- LiveCodeBench Pro:90.8
- GPQA-Diamond:95.5
其中,LiveCodeBench與LiveCodeBench Pro是兩項不同的程式能力測試,後者使用更高難度的題目。Fugu Ultra在標準版LiveCodeBench取得93.2、在進階版LiveCodeBench Pro取得90.8。作為對照,標準版Fugu在LiveCodeBench為92.9,可見Ultra在此項的領先幅度有限。
Sakana AI表示,Fugu Ultra的整體表現已達到與Anthropic Fable 5及Mythos Preview「肩並肩(shoulder-to-shoulder)」的水準。值得注意的是,Sakana官方並未宣稱Fugu Ultra全面擊敗Fable 5,僅主張其能力已可與這些前沿模型比擬。
Q6:Fugu Ultra的價格跟其他模型比,算貴還是便宜?
A:單看牌價,它落在前沿模型常見區間;但判斷貴不貴,重點在於「每完成一個任務的總成本」,而非每token單價。
Sakana AI官方定價顯示,Fugu Ultra每100萬token輸入收費5美元、輸出30美元、快取輸入0.5美元。若上下文長度超過272K token,價格提高為輸入10美元、輸出45美元、快取輸入1美元。
這個價格本身不算低。Fugu Ultra主打的價值在於高難度任務、多模型協作與供應鏈韌性,而非單純的低價。
真正的成本關鍵在於使用場景。若任務很簡單,例如大量分類、短文改寫、格式轉換,使用單一模型通常更划算。若任務需要多步驟推理、程式分析、資料交叉驗證或研究型工作,Fugu Ultra的價值才比較容易顯現。
Q7:Fugu為什麼一直強調「不受出口管制風險影響」?
A:因為產品發布時機正好碰上Anthropic的模型存取風波。
2026年6月,美國政府以國家安全為由,要求Anthropic暫停外國人士存取Fable 5與Mythos 5等前沿模型。Anthropic為求合規,最終關閉這兩個模型的全球存取權限,引發市場對AI模型供應鏈風險的討論。
這也讓企業重新思考一個問題:如果核心服務完全建立在單一模型供應商之上,一旦該模型因政策、法規或商業因素停止提供服務,應用系統是否還能繼續運作?
Sakana AI在發布稿中因此特別強調,Fugu的多模型架構能降低對單一供應商的依賴,並以「without the risk of export controls(不受出口管制風險影響)」描述產品定位。
不過這並不代表Fugu完全不使用美國模型,也不代表它可以無視出口管制。比較準確的理解是,Fugu希望透過可替換的代理池與多模型協作架構,讓企業在模型來源之間保留更大彈性,避免核心系統被單一供應商綁死。
Q8:為什麼「日本做出Fugu」特別受到關注?
A:因為它代表日本AI產業正在尋找不同於美國科技巨頭的競爭路線。
目前全球最強大的基礎模型,大多來自OpenAI、Anthropic與Google等美國企業。要在模型規模、算力與資金上正面競爭,難度極高。
相較之下,Sakana AI選擇從模型編排(Model Orchestration)與代理人協作(Agent Collaboration)切入,希望透過系統整合能力提升整體表現。
這也呼應日本近期對「AI自主能力」的焦慮。日本數位大臣松本剛久(Hisashi Matsumoto)於2026年6月5日警告,日本若無法跟上AI發展速度,未來可能淪為「AI殖民地(AI colony)」。
值得補充的是,松本這番話原本是為一項放寬資料使用同意規範的修法辯護。該修法涉及AI開發者能否在特定條件下使用醫療紀錄、犯罪紀錄等敏感資料訓練模型,因此在日本國內也引發隱私與個資保護爭議。
但「避免在AI時代受制於外國技術」的核心焦慮,與Fugu所訴求的降低單一供應商依賴,確實存在相互呼應之處。
某種程度上,Fugu代表的不只是一項新產品,更是日本AI產業試圖建立另一條技術路線:先不追求打造最大的模型,而是先打造最能整合模型的系統。
此外,Sakana並未選擇與OpenAI正面競爭基礎模型,而是試圖建立一套可以整合各家模型的新平台。若未來AI模型逐漸商品化,這類模型編排平台也可能成為新的競爭焦點。